Publications
2025
- Anirudh Iyengar Kaniyar Narayana Iyengar, Srija Mukhopadhyay, Adnan Qidwai, and 3 more authorsIn IJCNLP-AACL Main, 2025
InterChart is a diagnostic benchmark for assessing how well vision-language models reason across multiple related charts a core skill for scientific reports, finance, and public dashboards. Unlike prior single-chart benchmarks, InterChart covers diverse question types from entity inference and trend correlation to numerical estimation and abstract multi-step reasoning grounded in 2–3 thematically or structurally related charts. We organize the benchmark into three tiers of increasing difficulty: (1) factual reasoning over individual charts, (2) integrative analysis across synthetically aligned chart sets, and (3) semantic inference over visually complex, real-world chart pairs. Evaluations on state-of-the-art open- and closed-source VLMs reveal consistent accuracy drops as visual complexity rises, while chart decomposition improves performance highlighting current limitations in cross-chart integration. Overall, InterChart provides a rigorous framework for advancing multimodal reasoning in complex, multi-visual settings. Dataset scope (high level): 5,214 validated QA pairs spanning three subsets DECAF, SPECTRA, and STORM across 1,012 multi-chart contexts and 2,706 unique chart images.
@inproceedings{interchart2025, title = {InterChart : Benchmarking Visual Reasoning Across Decomposed and Distributed Chart Information}, author = {Kaniyar Narayana Iyengar, Anirudh Iyengar and Mukhopadhyay, Srija and Qidwai, Adnan and Singh, Shubhankar and Roth, Dan and Gupta, Vivek}, booktitle = {IJCNLP-AACL Main}, year = {2025}, url = {https://arxiv.org/abs/2508.07630}, data = {https://huggingface.co/datasets/interchart/Interchart}, } - Manan Roy Choudhury, Anirudh Iyengar Kaniyar Narayana Iyengar, Shikhhar Siingh, and 2 more authorsIn Findings of the Association for Computational Linguistics: EMNLP, 2025
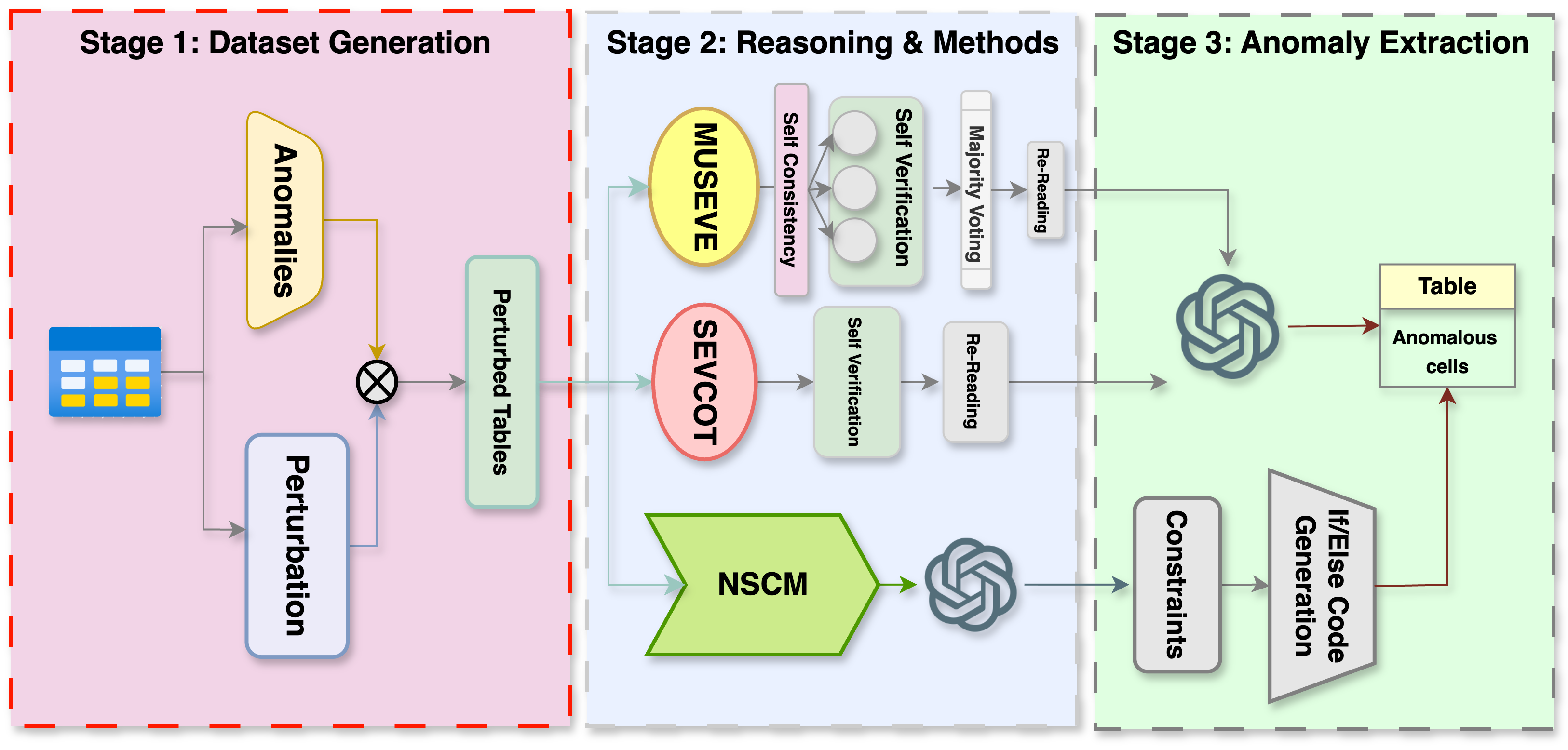
We study the capabilities of large language models (LLMs) in detecting fine-grained anomalies in tabular data. Specifically, we examine: (1) how well LLMs can identify diverse anomaly types—including factual, logical, temporal, and value-based errors; (2) the impact of prompt design and prompting strategies; and (3) the effect of table structure and anomaly type on detection accuracy. To this end, we introduce TABARD, a new benchmark constructed by perturbing tables from WikiTQ, FeTaQA, Spider, and BEAVER. The dataset spans multiple domains and eight anomaly categories, including paired clean and corrupted tables. We evaluate LLMs using direct, indirect, and Chain-of-Thought (CoT) prompting. Our results reveal notable limitations in standard prompting, especially for complex reasoning tasks and longer tables. To overcome these issues, we propose a unified framework combining multi-step prompting, self-verification, and constraint-based rule execution.
@inproceedings{tabard2025, title = {TABARD: A Novel Benchmark for Tabular Anomaly Analysis, Reasoning and Detection}, author = {Choudhury, Manan Roy and Kaniyar Narayana Iyengar, Anirudh Iyengar and Siingh, Shikhhar and Sugeeth, Raghavendra and Gupta, Vivek}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP}, pages = {21783--21817}, year = {2025}, url = {https://openreview.net/forum?id=8Y1G4XD3vR}, data = {https://github.com/TABARD-emnlp-2025/TABARD-dataset}, }